
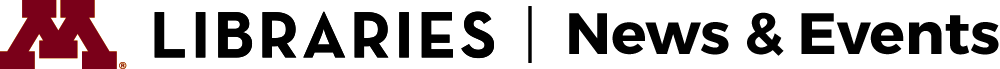
This month, the University Archives reaches a milestone — our collection now includes 20 years of University of Minnesota websites.
Those 20 years chronicle an irreplaceable source of the University’s history, as much as they contain the evidence of the web’s swift evolution in style. Our umn.edu websites were once designed for the mighty Netscape browser. Now, they run on platforms that need to be responsive to multiple web devices.

A screenshot of the earliest available U of M homepage, from 1997.
Without intervention, previous versions of a website are lost once the page is updated. This includes not just the page design and layout, but any information or files not included in the next iteration of the page.
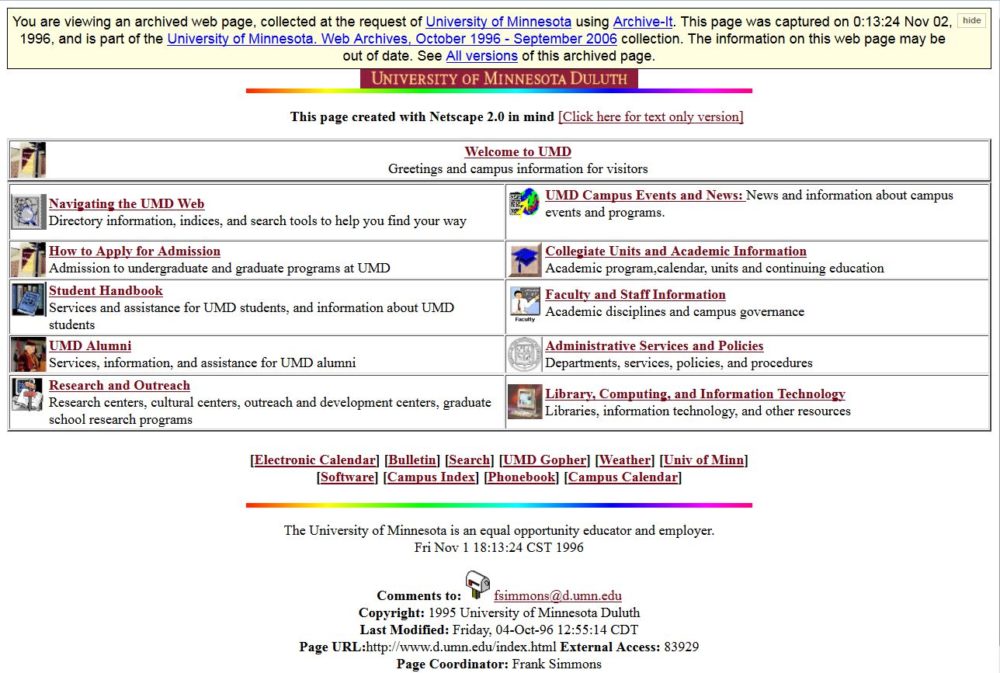
Screenshot of Duluth, 1996.

Screenshot of Morris, 1996.
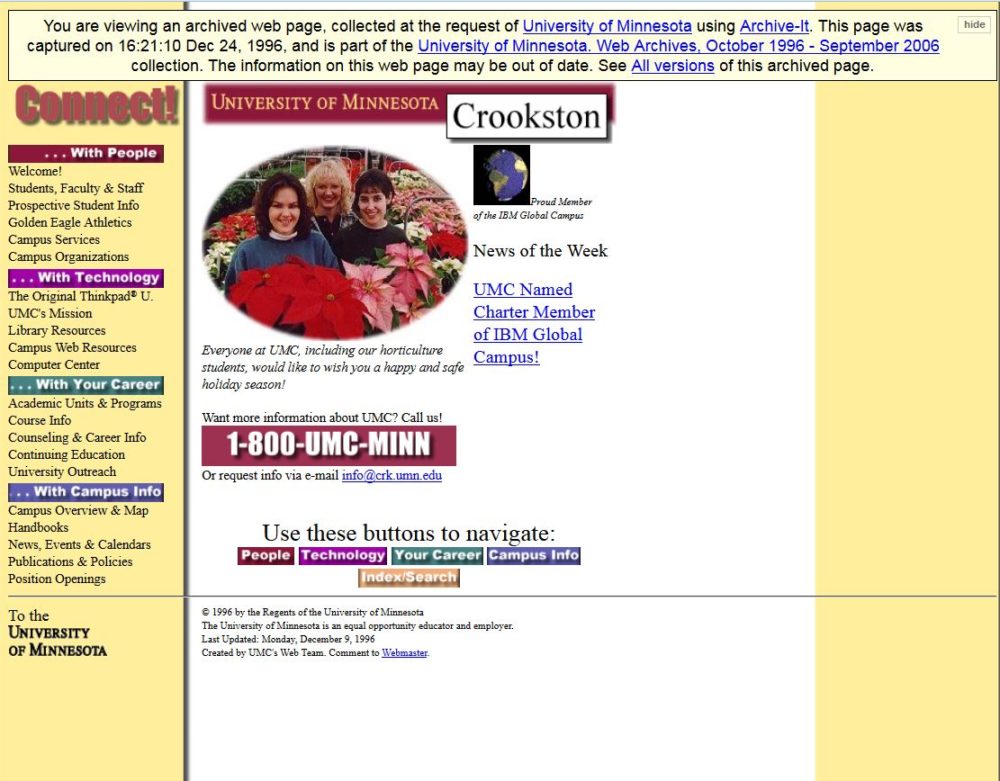
Screenshot of Crookston, 1996.
The University Archives works to prevent the loss of our online institutional history by archiving the web pages within the umn.edu domain. It is another way that we serve our mandate to collect and make available the history of the University.
Our web archives go back to 1996 — the year that the Internet Archive created the software that makes web archiving possible. But the University’s first website launched earlier than that. We don’t know the exact date that it launched, but it could not have been before 1993, when the Mosaic browser was first released.

An early web page from the Academic Health Center. The AHC’s online newsletter, “this thursday,” was offered to readers via the web and the Gopher protocol.
In order to archive this online content, staff in the University Archives identify unique URLs related to the University’s research and teaching. We then direct a website crawler to navigate and save the web pages, their style-sheets, and any content (such as PDF documents or images) that are a component of the website.
As much of the site is crawled as possible, which then allows the website to be navigated as if it were live. For those familiar with the Wayback Machine, it is a similar process, but we focus solely on UMN domains. It’s not always a perfect process, however. Sometimes an error creeps in from the crawler, and sometimes a University website cannot be completely crawled and information remains missing.
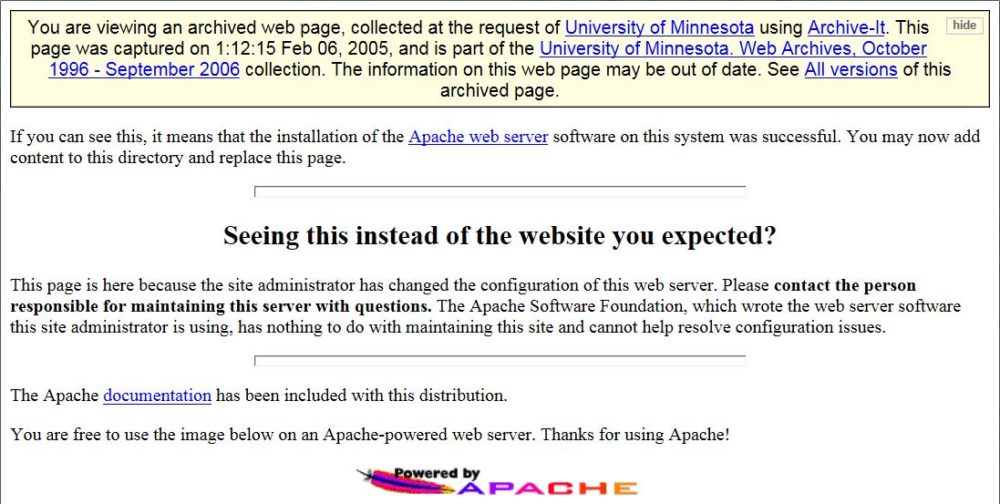
Sometimes we find errors like these in our archived sites – the original website had a configuration error that we have captured and saved.

Sometimes the web crawler doesn’t capture all of the content of a page, such as the images on this 2004 Twin Cities homepage.
We have 1.2TB of web data, which includes millions of unique web pages from various umn.edu domains between 1996-2016. It’s a large, if incomplete, source of information, capturing campus events, the evolution and history of schools and departments at the university, blogs and news from many different university sources, and research from faculty, labs, and centers. Sometimes websites provide unexpected insights, such as the rapid evolution of MSI’s logo over time to no logo at all.
Minnesota Supercomputing Institute’s website, 1998.
Minnesota Supercomputing Institute’s website, 1999.
Minnesota Supercomputing Institute’s website, 2003.
Minnesota Supercomputing Institute’s website, 2016.
Besides fueling nostalgia, the web archives are available for research and discovery. For 11 years (2004-2015), the University Libraries hosted the UThink blogging platform. It contained over 18,000 separate blogs with nearly 44,000 contributing authors. As a digital archive it is truly unique. It provided a sample of University life/history that could not be gathered any other way. It showed activism, student life, scholarly work, course content, departmental publications and news, one-time projects, field notes, travel logs, and more.
All of that information is now held within our web archives.

UThink Blog homepage, 2006
The entirety of our web collection can be accessed at our University of Minnesota Archive-It collection page.

— Valerie Collins is the Digital Repositories and Records Archivist. To learn more about the University of Minnesota Archives, please visit www.lib.umn.edu/uarchives.


